
Sql Server數據庫類似正則表達式的字符處理問題
SQL Serve提供了簡單的字符模糊匹配功能,比如:like, patindex,不過對于某些字符處理場景還顯得并不足夠,日常碰到的幾個問題有:...
SQL Serve提供了簡單的字符模糊匹配功能,比如:like, patindex,不過對于某些字符處理場景還顯得并不足夠,日常碰到的幾個問題有:
1. 同一個字符/字符串,出現了多少次
2. 同一個字符,第N次出現的位置
3. 多個相同字符連續,合并為一個字符
4. 是否為有效IP/身份證號/手機號等
一. 同一個字符/字符串,出現了多少次
同一個字符,將其替換為空串,即可計算
declare@textvarchar(1000)declare@strvarchar(10)set@text ='ABCBDBE'set@str ='B'selectlen(@text) - len(replace(@text,@str,''))
同一個字符串,仍然是替換,因為是多個字符,方法1替換后需要做一次除法;方法2替換時增加一個字符,則不需要
--方法1declare@textvarchar(1000)declare@strvarchar(10)set@text ='ABBBCBBBDBBBE'set@str ='BBB'select(len(@text) - len(replace(@text,@str,'')))/len(@str)--方法2declare@textvarchar(1000)declare@strvarchar(10)set@text ='ABBBCBBBDBBBE'set@str ='BBB'selectlen(replace(@text,@str,@str+'_')) - len(@text)
二. 同一個字符/字符串,第N次出現的位置
SQL SERVER定位字符位置的函數為CHARINDEX:
CHARINDEX ( expressionToFind , expressionToSearch [ , start_location ] )
可以從指定位置起開始檢索,但是不能取第N次出現的位置,需要自己寫SQL來補充,有以下幾種思路:
1. 自定義函數, 循環中每次為charindex加一個計數,直到為N
if object_id('NthChar','FN')isnotnulldropfunctionNthcharGOcreatefunctionNthChar(@source_stringasnvarchar(4000),@sub_stringasnvarchar(1024),@nthasint)returnsintasbegindeclare@postionintdeclare@countintset@postion = CHARINDEX(@sub_string, @source_string)set@count= 0while @postion > 0beginset@count= @count+ 1if @count= @nthbeginbreakendset@postion = CHARINDEX(@sub_string, @source_string, @postion + 1)Endreturn@postionendGO--select dbo.NthChar('abcabc','abc',2)--4
2. 通過CTE,對待處理的整個表字段操作, 遞歸中每次為charindex加一個計數,直到為N
if object_id('tempdb..#T')isnotnulldroptable#Tcreatetable#T(source_string nvarchar(4000))insertinto#Tvalues(N'我們我們')insertinto#Tvalues(N'我我哦我')declare@sub_string nvarchar(1024)declare@nthintset@sub_string = N'我們'set@nth = 2;withT(source_string, starts, pos, nth)as(selectsource_string, 1, charindex(@sub_string, source_string), 1from#tunionallselectsource_string, pos + 1, charindex(@sub_string, source_string, pos + 1), nth+1fromTwherepos > 0)selectsource_string, pos, nthfromTwherepos <> 0andnth = @nthorderbysource_string, starts--source_string pos nth--我們我們 3 2
3. 借助數字表 (tally table),到不同起點位置去做charindex,需要先自己構造個數字表
--numbers/tally tableIF EXISTS (select*fromdbo.sysobjectswhereid = object_id(N'[dbo].[Numbers]')andOBJECTPROPERTY(id, N'IsUserTable') = 1)DROPTABLEdbo.Numbers--===== Create and populate the Tally table on the flySELECTTOP1000000IDENTITY(int,1,1)ASnumberINTOdbo.NumbersFROMmaster.dbo.syscolumns sc1,master.dbo.syscolumns sc2--===== Add a Primary Key to maximize performanceALTERTABLEdbo.NumbersADDCONSTRAINTPK_numbers_numberPRIMARYKEYCLUSTERED (number)--===== Allow the general public to use itGRANTSELECTONdbo.NumbersTOPUBLIC--以上數字表創建一次即可,不需要每次都重復創建DECLARE@source_string nvarchar(4000),@sub_string nvarchar(1024),@nthintSET@source_string ='abcabcvvvvabc'SET@sub_string ='abc'SET@nth = 2;WITHTAS(SELECTROW_NUMBER() OVER(ORDERBYnumber)ASnth,numberAS[PositionInString]FROMdbo.Numbers nWHEREn.number <= LEN(@source_string)ANDCHARINDEX(@sub_string, @source_string, n.number)-number = 0----OR--AND SUBSTRING(@source_string,number,LEN(@sub_string)) = @sub_string)SELECT*FROMTWHEREnth = @nth
4. 通過CROSS APPLY結合charindex,適用于N值較小的時候,因為CROSS APPLY的次數要隨著N的變大而增加,語句也要做相應的修改
declare@Ttable(source_string nvarchar(4000))insertinto@Tvalues('abcabc'),('abcabcvvvvabc')declare@sub_string nvarchar(1024)set@sub_string ='abc'selectsource_string,p1.posasno1,p2.posasno2,p3.posasno3from@Tcrossapply (select(charindex(@sub_string, source_string)))asP1(Pos)crossapply (select(charindex(@sub_string, source_string, P1.Pos+1)))asP2(Pos)crossapply (select(charindex(@sub_string, source_string, P2.Pos+1)))asP3(Pos)
5. 在SSIS里有內置的函數,但T-SQL中并沒有
--FINDSTRING in SQL Server 2005 SSISFINDSTRING([yourColumn],"|", 2),--TOKEN in SQL Server 2012 SSISTOKEN(Col1,"|",3)
注:不難發現,這些方法和字符串拆分的邏輯是類似的,只不過一個是定位,一個是截取,如果要獲取第N個字符左右的一個/多個字符,有了N的位置,再結合substring去截取即可;
三. 多個相同字符連續,合并為一個字符
最常見的就是把多個連續的空格合并為一個空格,解決思路有兩個:
1. 比較容易想到的就是用多個replace
但是究竟需要replace多少次并不確定,所以還得循環多次才行
--把兩個連續空格替換成一個空格,然后循環,直到charindex檢查不到兩個連續空格declare@strvarchar(100)set@str='abc abc kljlk kljkl'while(charindex(' ',@str)>0)beginselect@str=replace(@str,' ',' ')endselect@str
2. 按照空格把字符串拆開
對每一段拆分開的字符串trim或者replace后,再用一個空格連接,有點繁瑣,沒寫代碼示例,如何拆分字符串可參考:“第N次出現的位置”;
四. 是否為有效IP/身份證號/手機號等
類似IP/身份證號/手機號等這些字符串,往往都有自身特定的規律,通過substring去逐位或逐段判斷是可以的,但SQL語句的方式往往性能不佳,建議嘗試正則函數,見下。
五. 正則表達式函數
1. Oracle
從10g開始,可以在查詢中使用正則表達式,它通過一些支持正則表達式的函數來實現:
Oracle 10 gREGEXP_LIKEREGEXP_REPLACEREGEXP_INSTRREGEXP_SUBSTROracle 11g (新增)REGEXP_COUNT
Oracle用REGEXP函數處理上面幾個問題:
(1) 同一個字符/字符串,出現了多少次
selectlength(regexp_replace('123-345-566','[^-]',''))fromdual;selectREGEXP_COUNT('123-345-566','-')fromdual;--Oracle 11g
(2) 同一個字符/字符串,第N次出現的位置
不需要正則,ORACLE的instr可以直接查找位置:
instr('source_string','sub_string' [,n][,m])
n表示從第n個字符開始搜索,缺省值為1,m表示第m次出現,缺省值為1。
select instr('abcdefghijkabc','abc', 1, 2) position from dual;
(3) 多個相同字符連續,合并為一個字符
select regexp_replace(trim('agc f f '),'\s+',' ') from dual;
(4) 是否為有效IP/身份證號/手機號等
--是否為有效IPWITHIPAS(SELECT'10.20.30.40'ip_addressFROMdualUNIONALLSELECT'a.b.c.d'ip_addressFROMdualUNIONALLSELECT'256.123.0.254'ip_addressFROMdualUNIONALLSELECT'255.255.255.255'ip_addressFROMdual)SELECT*FROMIPWHEREREGEXP_LIKE(ip_address,'^(([0-9]{1}|[0-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\.){3}([0-9]{1}|[0-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])$');--是否為有效身份證/手機號,暫未舉例
2. SQL Server
目前最新版本為SQL Server 2017,還沒有對REGEXP函數的支持,需要通用CLR來擴展,如下為CLR實現REG_REPLACE:
--1. 開啟 CLREXECsp_configure'show advanced options','1'GORECONFIGUREGOEXECsp_configure'clr enabled','1'GORECONFIGUREGOEXECsp_configure'show advanced options','0';GO
2. 創建 Assembly
--3. 創建 CLR 函數CREATE FUNCTION [dbo].[regex_replace](@input [nvarchar](4000), @pattern [nvarchar](4000), @replacement [nvarchar](4000))RETURNS [nvarchar](4000) WITH EXECUTE AS CALLER, RETURNS NULL ON NULL INPUTASEXTERNAL NAME [RegexUtility].[RegexUtility].[RegexReplaceDefault]GO--4. 使用regex_replace替換多個空格為一個空格select dbo.regex_replace('agc f f ','\s+',' ');
注:通過CLR實現更多REGEXP函數,如果有高級語言開發能力,可以自行開發;或者直接使用一些開源貢獻也行,比如:http://devnambi.com/2016/sql-server-regex/
小結:
1. 非正則SQL語句的思路,對不同數據庫往往都適用;
2. 正則表達式中的規則(pattern) 在不同開發語言里,有很多語法是相通的,通常是遵守perl或者linux shell中的sed等工具的規則;
3. 從性能上來看,通用SQL判斷 > REGEXP函數 > 自定義SQL函數。
總結:以上所述是小編給大家介紹的SqlServer類似正則表達式的字符處理問題,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。

Mysql數據庫使用from與join兩表查詢的方法區別總結
文章主要給大家介紹了關于mysql使用from與join兩表查詢的區別的相關資料,文中通過示例代碼介紹的非常詳細,對大家的學習或者工作具有一定的參考學習價值,需要的朋友們下面...
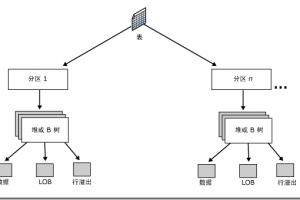
SQL Server數據庫中表和索引結構存儲的原理及如何加快搜索速度分析
本文詳細分析了SQL Server中表和索引結構存儲的原理以及對于如何加快搜索速度和提高效率等方面做了詳細的分析,以下是主要內容。...
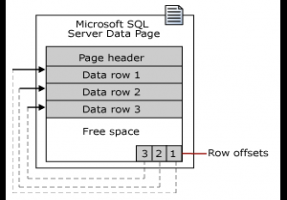
SQL Server Page數據庫結構深入分析
SQL Server存儲數據的基本單元是Page,每一個Page的大小是8KB,數據文件是由Page構成的。在同一個數據庫上,每一個Page都有一個唯一的資源標識,標識符由三部分組成...
基于Sql server數據庫的四種分頁方式總結
下面小編就為大家分享一篇基于sqlserver的四種分頁方式總結,具有很好的參考價值,希望對大家有所幫助。一起跟隨小編過來看看吧。...
SQL Server 2016數據庫快照代理過程詳解
本文我們通過SQL Server 2016一個實例數據表,給大家詳細分析了快照代理過程遇到的問題和解決辦法,并對快照生成過程做了詳細說明,以下是全部內容:...

SQL Server 全文搜索功能、全文索引方式介紹
SQL Server 的全文搜索(Full-Text Search)是基于分詞的文本檢索功能,依賴于全文索引。全文索引不同于傳統的平衡樹(B-Tree)索引和列存儲索引,它是由數據表構成的,稱作倒轉索引(Invert Index),存儲分詞和行的唯一鍵的映射關系。...

關于SQL Serve數據庫r帳號被禁用的處理方法
若發現SQL Serve所有帳號不小心被禁用了,這個時候怎么辦?用重裝嗎?不用,仔細看小白是怎么一步一步解開這個謎題的。首先需要Windows帳號設置里重新添加一個新帳號。并將其添加到...

SQL數據庫查詢優化技巧提升網站訪問速度的方法
在這篇文章中,我將介紹如何識別導致性能出現問題的查詢,如何找出它們的問題所在,以及快速修復這些問題和其他加快查詢速度的方法。 你一定知道,一個快速訪問的網站能讓用...
SQL數據庫開發中的SSIS 延遲驗證方法
驗證是一個事件,該事件在Package執行時,第一個被觸發,驗證能夠避免SSIS引擎執行一個有異常的Package或Task。延遲驗證(DelayValidation)是把驗證操作延遲到Package真正運行(run-ti...
SQL Server數據庫建立新用戶及關聯數據庫的方法教程
本文講的是SQLserver數據庫創建新用戶方法以及賦予此用戶特定權限的方法,非常的簡單實用,有需要的小伙伴可以參考下...